Build and Sign WebExtensions with CircleCI
Once Planet Mozilla updated with my last post, I got a few bug reports and feature requests for mailman-admin-helper, along with a pull request (Thanks, TheOne!). Clearly I'm not the only person who isn't a fan of our mailing list admin.
Before landing anything, I decided to see if I could get automatic builds running so that I wouldn't have to pull a build pull requests myself when I want to test them. What I ended up with, however, does a bit more than that; it also runs lints, and even signs and uploads new releases when I push a new tag.
We use CircleCI on Normandy, so I defaulted to using them for this as well. I'll walk through the sections, but here's the entire circle.yml file I ended up with:
machine:
node:
version: 7.10.0
dependencies:
override:
- sudo apt-get update; sudo apt-get install jq
- go get -u github.com/tcnksm/ghr
- npm install -g web-ext
compile:
override:
- web-ext build
- mv web-ext-artifacts $CIRCLE_ARTIFACTS
test:
override:
- web-ext lint --self-hosted
deployment:
release:
tag: /v[0-9]+(\.[0-9]+)*/
owner: Osmose
commands:
- jq --arg tag "${CIRCLE_TAG:1}" '.version = $tag' manifest.json > tmp.json && mv tmp.json manifest.json
- web-ext sign --api-key $AMO_API_KEY --api-secret $AMO_API_SECRET
- ghr -u Osmose $CIRCLE_TAG web-ext-artifacts
If you want to adapt this to your own project, you'll want to change the deployment.release.owner field to the Github account hosting your WebExtension, and add the following environment variables to your CircleCI project config (NOT your circle.yml file, which is committed to your repo):
-
GITHUB_TOKEN: A personal access token with either thepublic_repoorrepopermissions, depending on whether your repository is public or private. -
AMO_API_KEY: The JWT issuer field from your addons.mozilla.org API Credentials. -
AMO_API_SECRET: The JWT secret field from your addons.mozilla.org API Credentials.
How does it work?
circle.yml files are split into phases. Each phase has a default action that is overridden with the override key.
machine:
node:
version: 7.10.0
The machine phase defines the machine used to run your build. Here we're just making sure that we have a recent version of Node.
dependencies:
override:
- sudo apt-get update; sudo apt-get install jq
- go get -u github.com/tcnksm/ghr
- npm install -g web-ext
The dependencies step is for installing libraries and programs that your build needs. Our build process has three dependencies:
-
jq: A command-line JSON processor that we use to replace the version number in
manifest.json. -
ghr: A tool for uploading artifacts to Github release pages. Our build image already has a recent version of Go installed, so we install this via [go get][].
-
web-ext: Mozilla's command-line tool for building and testing WebExtensions.
compile:
override:
- web-ext build
- mv web-ext-artifacts $CIRCLE_ARTIFACTS
The compile step is used to build your project before testing. While we aren't running any tests that need a built add-on, this is a good time to build the add-on and upload it to the $CIRCLE_ARTIFACTS directory, which is saved and made available for download once the build is complete. This makes it easy to pull a ready-to-test build of the add-on from open pull requests.
test:
override:
- web-ext lint --self-hosted
The test step is for actually running your tests. We don't have automated tests for mailman-admin-helper, but web-ext comes with a handy lint command to help catch common errors.
One thing to note about CircleCI is that any commands that return non-zero return codes will stop the build immediately and mark it as failed, except for commands in the test step. test step commands will mark a build as failed, but will not stop other commands in the test step from running. This is useful for running multiple types of tests or lints because it allows you to see all of your failures instead of exiting early before running all of your tests.
deployment:
release:
tag: /v[0-9]+(\.[0-9]+)*/
owner: Osmose
commands:
- jq --arg tag "${CIRCLE_TAG:1}" '.version = $tag' manifest.json > tmp.json && mv tmp.json manifest.json
- web-ext sign --api-key $AMO_API_KEY --api-secret $AMO_API_SECRET
- ghr -u Osmose $CIRCLE_TAG web-ext-artifacts
The deployment section only runs on successful builds, and handles deploying your code. It's made up of multiple named sections, and each section must either have a branch or tag field describing the branches or tags that the section will run for.
In our case, we're using a regex that matches tags named like version numbers prefixed with v, e.g. v0.1.2. We also set the owner to my Github account so that forks will not run the deployment process.
The commands do three things:
-
Use
jqto modify theversionkey inmanifest.jsonto match the version number from the tag. Thevprefix is removed before the replacement. -
Use
web-extto build and sign the WebExtension, using API keys stored in environment variables. This creates an XPI file in theweb-ext-artifactsdirectory. -
Use
ghrto upload the contents ofweb-ext-artifacts(which should just by the signed XPI) to the tag on Github. This uses theGITHUB_TOKENenvironment variable for authentication.
The end result is that, whenever a new tag is pushed to the repository, CircleCI adds a signed XPI to the release page on Github automatically, without any human intervention. Convenient!
Feel free to steal this for your own WebExtension, or share any comments or suggestions either in the comments or directly on the mailman-admin-helper repository. Thanks for reading!
mailman-admin-helper: Mildly Easier Mailman Spam Management
Mozilla hosts a few Mailman instances1, and I run a few mailing lists on them. Our interface for managing incoming spam is... okay.
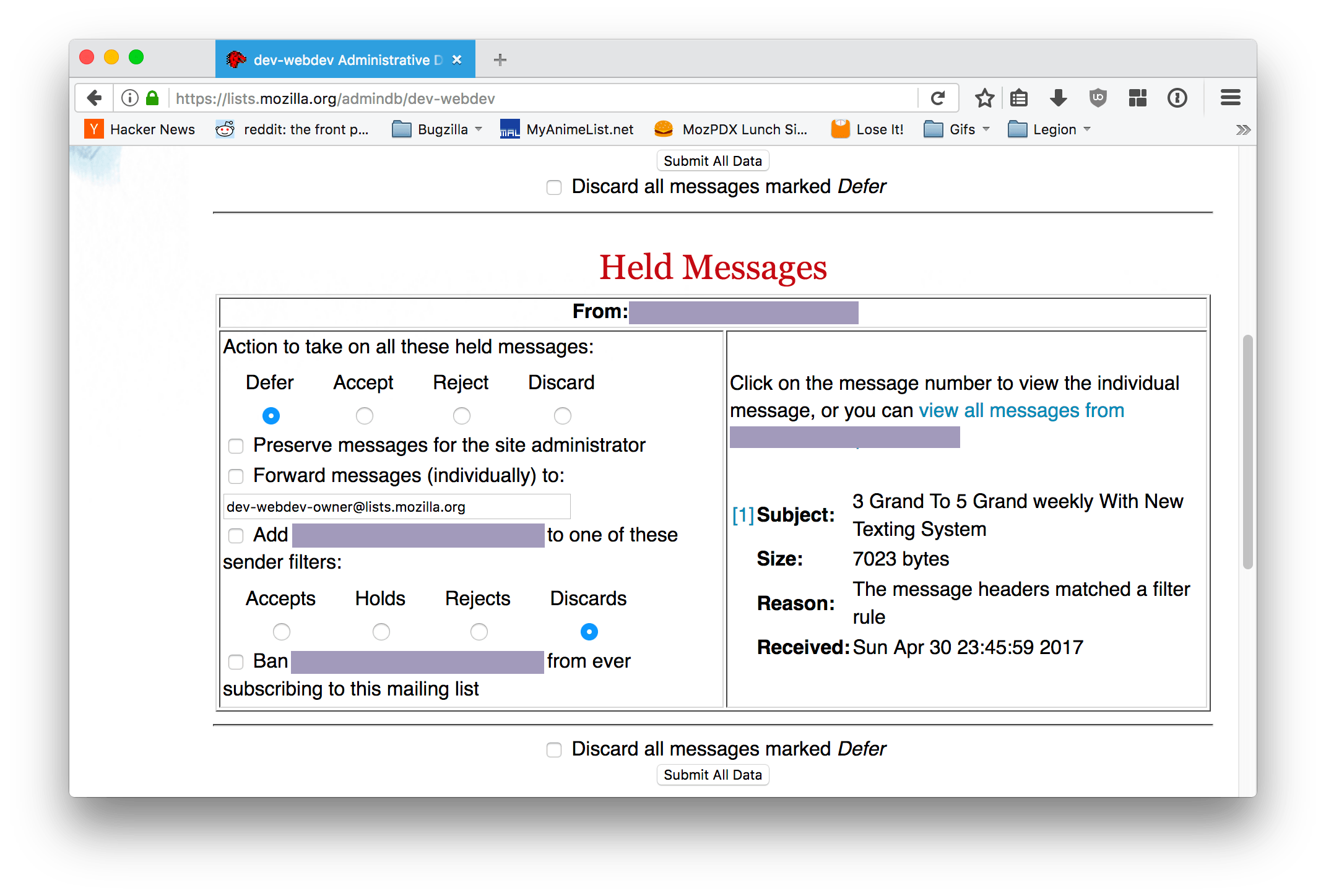
The form inputs are tiny. And it takes, like, 3 clicks to discard and blacklist spam per-sender. And, because I only learned about the options for filtering by spam headers within the past month, I had to use this interface on a daily basis for years.
Finally, about a year or so ago, I got fed up and wrote a bookmarklet that auto-clicked every form element needed to discard and blacklist every email on the page. Since it's rare for the lists I moderate to get legitimate emails that are marked for moderation, I didn't need anything more complex.
However, we recently updated our Mailman pages to use CSP, specifically the script-src none directive. Because the pages no longer accept any URL as valid for script execution, my bookmarklet stopped working. I searched online for workarounds and didn't find anything informative2.
Luckily, I happen to have experience making WebExtensions that inject content scripts into web pages. It's as simple as creating a manifest.json file:
{
"manifest_version": 2,
"name": "mailman-admin-helper",
"version": "0.1.1",
"applications": {
"gecko": {
"id": "mailman-admin-helper@mkelly.me"
}
},
"description": "Adds useful shortcuts to Mozilla Mailman admin.",
"content_scripts": [
{
"matches": [
"*://mail.mozilla.org/admindb/*",
"*://lists.mozilla.org/admindb/*"
],
"js": ["index.js"],
"css": ["index.css"]
}
]
}
The content_scripts key is where the magic happens. List some domains, write some JavaScript and CSS, and you're done! The web-ext tool makes testing, building, and signing the extension pretty painless.
An hour or two later, and I had finished my new WebExtension, mailman-admin-helper. After it is installed, the admin interface is greatly simplified:
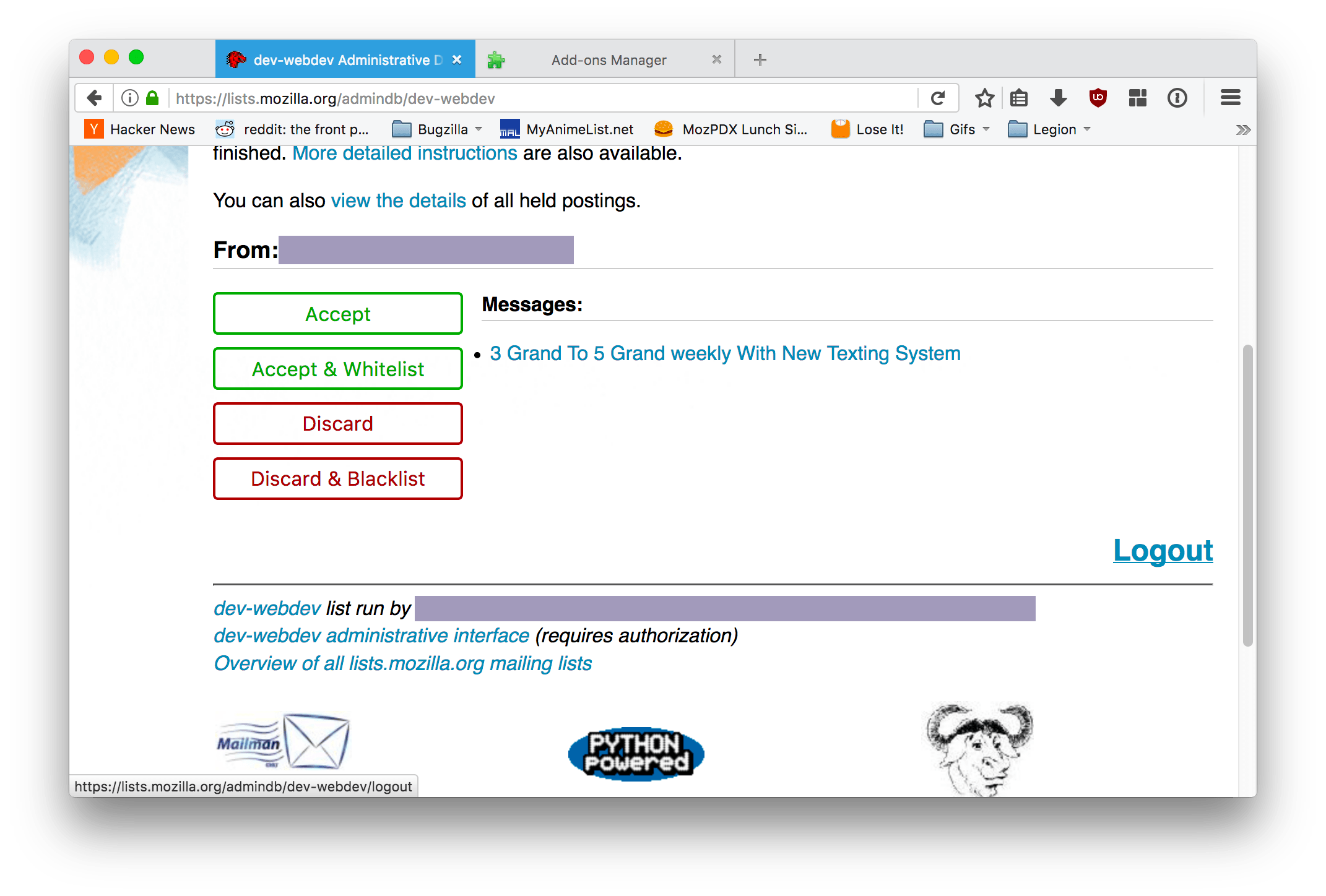
The block of checkboxes and radio buttons has been replaced by 4 buttons that immediately make their changes and refresh the page when clicked. And if you need to inspect and modify an individual email, you can still click through the email subject to get to the normal moderation page.
Granted, it cuts out a lot of functionality, but this extension is mostly meant for myself to use. Pull requests are welcome, though, in case anyone wants to add functionality that they commonly use.
Big thanks to the Add-ons team and community for making WebExtensions super-easy to use!
Footnotes
-
I'm not entirely sure why we have two, but it's cool. ↩
-
I did find bug 866522, which discusses the reason bookmarklets don't work with CSP, as well as some proposed fixes to Firefox and the (in my opinion, correct) wisdom that bookmarklets are a dead-end anyway. ↩
content-UITour.js
Recently I found myself trying to comprehend an unfamiliar piece of code. In this case, it was content-UITour.js, a file that handles the interaction between unprivileged webpages and UITour.jsm.
UITour allows webpages to highlight buttons in the toolbar, open menu panels, and perform other tasks involved in giving Firefox users a tour of the user interface. The event-based API allows us to iterate quickly on the onboarding experience for Firefox by controlling it via easily-updated webpages. Only a small set of Mozilla-owned domains are allowed access to the UITour API.
Top-level View
My first step when trying to grok unfamiliar JavaScript is to check out everything at the top-level of the file. If we take content-UITour.js and remove some comments, imports, and constants, we get:
var UITourListener = {
handleEvent(event) {
/* ... */
},
/* ... */
};
addEventListener("mozUITour", UITourListener, false, true);
Webpages that want to use UITour emit synthetic events with the name "mozUITour". In the snippet above, UITourListener is the object that receives these events. Normally, event listeners are functions, but they can also be EventListeners, which are simply objects with a handleEvent function.
According to Mossop's comment, content-UITour.js is loaded in browser.js. A search for firefox loadFrameScript brings up two useful pages:
-
nsIFrameScriptLoader, which describes how
loadFrameScripttakes our JavaScript file and loads it into a remote frame. If you don't innately know what a remote frame is, then you should read... -
Message manager overview, which gives a great overview of frame scripts and how they relate to multi-process Firefox. In particular,
browser.jsseems to be asking for a browser message manager.
It looks like content-UITour.js is loaded for each tab with a webpage open, but it can do some more privileged stuff than a normal webpage. Also, the global object seems to be window, referring to the browser window containing the webpage, since events from the webpage are bubbling up to it. Neat!
Events from Webpages
So what about handleEvent?
handleEvent(event) {
if (!Services.prefs.getBoolPref("browser.uitour.enabled")) {
return;
}
if (!this.ensureTrustedOrigin()) {
return;
}
addMessageListener("UITour:SendPageCallback", this);
addMessageListener("UITour:SendPageNotification", this);
sendAsyncMessage("UITour:onPageEvent", {
detail: event.detail,
type: event.type,
pageVisibilityState: content.document.visibilityState,
});
},
If UITour itself is disabled, or if the origin of the webpage we're registered on isn't trustworthy, events are thrown away. Otherwise, we register UITourListener as a message listener, and send a message of our own.
I remember seeing addMessageListener and sendAsyncMessage on the browser message manager documentation; they look like a fairly standard event system. But where are these events coming from, and where are they going to?
In lieu of any better leads, our best bet is to search DXR for "UITour:onPageEvent", which leads to nsBrowserGlue.js. Luckily for us, I've actually heard of this file before: it's a grab-bag for things that need to happen to set up Firefox that don't fit anywhere else. For our purposes, it's enough to know that stuff in here gets run once when the browser starts.
The lines in question:
// Listen for UITour messages.
// Do it here instead of the UITour module itself so that the UITour module is lazy loaded
// when the first message is received.
var globalMM = Cc["@mozilla.org/globalmessagemanager;1"].getService(Ci.nsIMessageListenerManager);
globalMM.addMessageListener("UITour:onPageEvent", function(aMessage) {
UITour.onPageEvent(aMessage, aMessage.data);
});
Oh, I remember reading about the global message manager! It covers every frame. This seems to be where all the events coming up from individual frames get gathered and passed to UITour. That UITour variable is coming from a clever lazy-import block at the top:
[
/* ... */
["UITour", "resource:///modules/UITour.jsm"],
/* ... */
].forEach(([name, resource]) => XPCOMUtils.defineLazyModuleGetter(this, name, resource));
In other words, UITour refers to the module in UITour.jsm, but it isn't loaded until we receive our first event, which helps make Firefox startup snappier.
For our purposes, we're not terribly interested in what UITour does with these messages, as long as we know how they're getting there. We are, however, interested in the messages that we're listening for: "UITour:SendPageCallback" and "UITour:SendPageNotification". Another DXR search tells me that those are in UITour.jsm. A skim of the results shows that these messages are used for things like notifying the webpage when an operation is finished, or returning information that was requested by the webpage.
To summarize:
-
handleEventin the content process triggers behavior fromUITour.jsmin the chrome process by sending and receiving messages sent through the message manager system. -
handleEventchecks that the origin of a webpage is trustworthy before doing anything. -
The UITour module in the chrome process is not initialized until a webpage emits an event for it.
The rest of the content-UITour.js is split between origin verification and sending events back down to the webpage.
Verifying Webpage URLs
Next, let's take a look at ensureTrustedOrigin:
ensureTrustedOrigin() {
if (content.top != content)
return false;
let uri = content.document.documentURIObject;
if (uri.schemeIs("chrome"))
return true;
if (!this.isSafeScheme(uri))
return false;
let permission = Services.perms.testPermission(uri, UITOUR_PERMISSION);
if (permission == Services.perms.ALLOW_ACTION)
return true;
return this.isTestingOrigin(uri);
},
MDN tells us that content is the Window object for the primary content window; in other words, the webpage. top, on the other hand, is the topmost window in the window hierarchy (relevant for webpages that get loaded in iframes). Thus, the first check is to make sure we're not in some sort of frame. Without this, a webpage could control when UITour executes things by loading a whitelisted origin in an iframe1.
documentURIObject lets us check the origin of the loaded webpage. chrome:// URIs get passed immediately, since they're already privileged. The next three checks are more interesting:
isSafeScheme
isSafeScheme(aURI) {
let allowedSchemes = new Set(["https", "about"]);
if (!Services.prefs.getBoolPref("browser.uitour.requireSecure"))
allowedSchemes.add("http");
if (!allowedSchemes.has(aURI.scheme))
return false;
return true;
},
This function checks the URI scheme to see if it's considered "safe" enough to use UITour functions. By default, https:// and about: pages are allowed. http:// pages are also allowed if the browser.uitour.requireSecure preference is false (it defaults to true).
Permissions
The next check is against the permissions system. The Services.jsm documentation says that Services.perms refers to an instance of the nsIPermissionManager interface. The check itself is easy to understand, but what's missing is how these permissions get added in the first place. A fresh Firefox profile has some sites already whitelisted for UITour, but where does that whitelist come from?
This is where DXR really shines. If we look at nsIPermissionManager.idl and click the name of the interface, a dropdown appears with several options. The "Find subclasses" option performs a search for "derived:nsIPermissionManager", which leads to the header file for nsPermissionManager.
We're looking for where the default permission values come from, so an in-page search for the word "default" eventually lands on a function named ImportDefaults. Clicking that name and selecting "Jump to definition" lands us inside nsPermissionManager.cpp, and the very first line of the function is:
nsCString defaultsURL = mozilla::Preferences::GetCString(kDefaultsUrlPrefName);
An in-page search for kDefaultsUrlPrefName leads to:
// Default permissions are read from a URL - this is the preference we read
// to find that URL. If not set, don't use any default permissions.
static const char kDefaultsUrlPrefName[] = "permissions.manager.defaultsUrl";
On my Firefox profile, the "permissions.manager.defaultsUrl" preference is set to resource://app/defaults/permissions:
# This file has default permissions for the permission manager.
# The file-format is strict:
# * matchtype \t type \t permission \t host
# * "origin" should be used for matchtype, "host" is supported for legacy reasons
# * type is a string that identifies the type of permission (e.g. "cookie")
# * permission is an integer between 1 and 15
# See nsPermissionManager.cpp for more...
# UITour
origin uitour 1 https://www.mozilla.org
origin uitour 1 https://self-repair.mozilla.org
origin uitour 1 https://support.mozilla.org
origin uitour 1 https://addons.mozilla.org
origin uitour 1 https://discovery.addons.mozilla.org
origin uitour 1 about:home
# ...
Found it! A quick DXR search reveals that this file is in /browser/app/permissions in the tree. I'm not entirely sure where that defaults bit in the URL is coming from, but whatever.
With this, we can confirm that the permissions check is where most valid uses of UITour are passed, and that this permissions file is where the whitelist of allowed domains lives.
isTestingOrigin
The last check in ensureTrustedOrigin falls back to isTestingOrigin:
isTestingOrigin(aURI) {
if (Services.prefs.getPrefType(PREF_TEST_WHITELIST) != Services.prefs.PREF_STRING) {
return false;
}
// Add any testing origins (comma-seperated) to the whitelist for the session.
for (let origin of Services.prefs.getCharPref(PREF_TEST_WHITELIST).split(",")) {
try {
let testingURI = Services.io.newURI(origin);
if (aURI.prePath == testingURI.prePath) {
return true;
}
} catch (ex) {
Cu.reportError(ex);
}
}
return false;
},
Remember those boring constants we ignored earlier? Here's one of them in action! Specifically, it's PREF_TEST_WHITELIST, which is set to "browser.uitour.testingOrigins".
This function appears to parse the preference as a comma-separated list of URIs. It fails early if the preference isn't a string, then splits the string and loops over each entry, converting them to URI objects.
The nsIURI documentation notes that prePath is everything in the URI before the path, including the protocol, hostname, port, etc. Using prePath, the function iterates over each URI in the preference and checks it against the URI of the webpage. If it matches, then the page is considered safe!
(And if anything fails when parsing URIs, errors are reported to the console using reportError and discarded.)
As the preference name implies, this is useful for developers who want to test a webpage that uses UITour without having to set up their local development environment to fake being one of the whitelisted origins.
Sendings Messages Back to the Webpage
The other remaining logic in content-UITour.js handles messages sent back to the content process from UITour.jsm:
receiveMessage(aMessage) {
switch (aMessage.name) {
case "UITour:SendPageCallback":
this.sendPageEvent("Response", aMessage.data);
break;
case "UITour:SendPageNotification":
this.sendPageEvent("Notification", aMessage.data);
break;
}
},
You may remember the Message manager overview, which links to documentation for several functions, including addMessageListener. We passed in UITourListener as the listener, which the documentation says should implement the nsIMessageListener interface. Thus, UITourListener.receiveMessage is called whenever messages are received from UITour.jsm.
The function itself is simple; it defers to sendPageEvent with slightly different parameters depending on the incoming message.
sendPageEvent(type, detail) {
if (!this.ensureTrustedOrigin()) {
return;
}
let doc = content.document;
let eventName = "mozUITour" + type;
let event = new doc.defaultView.CustomEvent(eventName, {
bubbles: true,
detail: Cu.cloneInto(detail, doc.defaultView)
});
doc.dispatchEvent(event);
}
sendPageEvent starts off with another trusted origin check, to avoid sending results from UITour to untrusted webpages. Next, it creates a custom event to dispatch onto the document element of the webpage. Webpages register an event listener on the root document element to receive data returned from UITour.
defaultView returns the window object for the document in question.
Describing cloneInto could take up an entire post on its own. In short, cloneInto is being used here to copy the object from UITour in the chrome process (a privileged context) for use in the webpage (an unprivileged context). Without this, the webpage would not be able to access the detail value at all.
And That's It!
It takes effort, but I've found that deep-dives like this are a great way to both understand a single piece of code, and to learn from the style of the code's author(s). Hopefully ya'll will find this useful as well!
Footnotes
-
While this isn't a security issue on its own, it gives some level of control to an attacker, which generally should be avoided where possible. ↩
Caching Async Operations via Promises
I was working on a bug in Normandy the other day and remembered a fun little trick for caching asynchronous operations in JavaScript.
The bug in question involved two asynchronous actions happening within a function. First, we made an AJAX request to the server to get an "Action" object. Next, we took an attribute of the action, the implementation_url, and injected a <script> tag into the page with the src attribute set to the URL. The JavaScript being injected would then call a global function and pass it a class function, which was the value we wanted to return.
The bug was that if we called the function multiple times with the same action, the function would make multiple requests to the same URL, even though we really only needed to download data for each Action once. The solution was to cache the responses, but instead of caching the responses directly, I found it was cleaner to cache the Promise returned when making the request instead:
export function fetchAction(recipe) {
const cache = fetchAction._cache;
if (!(recipe.action in cache)) {
cache[recipe.action] = fetch(`/api/v1/action/${recipe.action}/`)
.then(response => response.json());
}
return cache[recipe.action];
}
fetchAction._cache = {};
Another neat trick in the code above is storing the cache as a property on the function itself; it helps avoid polluting the namespace of the module, and also allows callers to clear the cache if they wish to force a re-fetch (although if you actually needed that, it'd be better to add a parameter to the function instead).
After I got this working, I puzzled for a bit on how to achieve something similar for the <script> tag injection. Unlike an AJAX request, the only thing I had to work with was an onload handler for the tag. Eventually I realized that nothing was stopping me from wrapping the <script> tag injection in a Promise and caching it in exactly the same way:
export function loadActionImplementation(action) {
const cache = loadActionImplementation._cache;
if (!(action.name in cache)) {
cache[action.name] = new Promise((resolve, reject) => {
const script = document.createElement('script');
script.src = action.implementation_url;
script.onload = () => {
if (!(action.name in registeredActions)) {
reject(new Error(`Could not find action with name ${action.name}.`));
} else {
resolve(registeredActions[action.name]);
}
};
document.head.appendChild(script);
});
}
return cache[action.name];
}
loadActionImplementation._cache = {};
From a nitpicking standpoint, I'm not entirely happy with this function:
- The name isn't really consistent with the "fetch" terminology from the previous function, but I'm not convinced they should use the same verb either.
- The Promise code could probably live in another function, leaving this one to only concern itself about the caching.
- I'm pretty sure this does nothing to handle the case of the script failing to load, like a 404.
But these are minor, and the patch got merged, so I guess it's good enough.
Pages